728x90
간단한 정리
6장 정리
6.1.1 랜덤 - 접근 메모리(RAM : Random Access Memory)
- 동적(DRAM) : 메인메모리, 그래픽 시스템의 프레임버퍼
- 정적(SRAM) : 캐시메모리
정적RAM(SRAM)
- 각 비트를 이중안전(bistable) 메모리 셀에 저장
- 두 가지 상태외 다른 상태들은 모두 불안정하다. - 역진자와 유사하다.
동적RAM(DRAM)
- 각 비트를 전하로 캐패시터에 저장
- 외란에 민감하다.
- DRAM 칩 내의 셀들은 슈퍼셀들로 나누어지며 각각은 DRAM셀들로 이루어진다. 슈퍼셀은 직사각형 배열이다.
- 정보는 pin이라고 부르는 외부 커넥터를 통해 칩의 안과 밖을 흘러 다닌다.
- 일반DRAM
- 슈퍼셀(i,j)의 내용을 읽으려면 메모리 컨트롤러는 행 주소i를 DRAM에 보내고, 다음에 열 주소j를 보낸다.
- 행 주소 i는 RAS(Row Access Strobe)요청
- 열 주소 j는 CAS(Column Access Strobe)요청
- DRAM을 선형 배열 대신 이차원 배열로 구성하는 한 가지 이유 : 주소핀을 줄이기 위해서 4→2개로 준다
메모리 모듈
- DRAM 칩은 메인 시스템 보드(머더보드)의 확장 슬롯에 꽂을 수 있는 메모리 모듈 형태로 패키징된다.
비휘발성 메모리
- SRAM과 DRAM은 전원이 꺼지면 정보를 잃어버리기 때문에 휘발성이다.
- 비휘발성 메모리는 전원이 꺼져도 정보를 유지한다.
- 일부의 경우 읽기 작업뿐만 아니라 쓰기 작업도 가능하지만 역사적인 이유로 이들은 모두 ROM이라고 부른다.
- ROM은 이들이 재기록 될 수 있는 횟수와 이들을 재기록 하는 방법으로 구별한다.
- ROM 디바이스에 저장된 프로그램들은 종종 펌웨어 라고 부른다.
메인메모리 접근하기
- 데이터는 ‘버스’라고 하는 공유된 전기회로를 통해서 프로세서와 DRAM 메인 메모리간에 앞 뒤로 교환된다. CPU와 메모리 간의 매 전송은 버스 트랜잭션이라고 부르는 일련의 단계를 통해 이뤄진다.
6.1.2 디스크 저장장치
디스크 구조
- 디스크들은 원판들로 구성된다. 원판은 두 개의 옆면, 표면으로 이루어져 있으며, 이들은 자성을 띤 기억물질로 코팅되어 있다.
- 각 표면은 트랙이라고 하는 여러개의 동심원 들로 이루어져 있다.
디스크의 동작
- 디스크는 구동팔의 끝에 연결된 읽기/쓰기 헤드를 사용해서 자성 표면에 저장된 비트를 읽거나 쓴다. 다중원판을 갖는 디스크는 각 표면마다 별도의 읽기/쓰기 헤드를 가진다.
- 디스크는 데이터를 섹터 크기의 블록으로 읽고 기록한다. 섹터에 접근하는 시간은 세 개의 주요 부분으로 이루어진다.
- 탐색시간
- 회전지연시간
- 전송시간
6.1.2 SolidStateDisk(SSD)
- 일종의 저장장치 기술, 플래시 메모리를 사용한다.
- SSD 패키지는 회전하는 디스크에서 기계적인 드라이브를 대체한 하나 이상의 플래시 메모리칩, 디스크 컨트롤러 같은 역할을 하는 하드웨어/펌웨어 장치이며, 논리블록들에 대한 요청들을 하부 물리 디바이스에 대한 접근으로 번역하는 플래시 번역 계층으로 이루어져 있다.
- 장점
- 반도체 메모리로 만들어서 움직이는 부품이 없으며, 따라서 회전하는 디스크보다 랜덤 접근시간이 훨씬 더 빠르다
- 더 작은 전력을 소모한다.
- 더 견고하다
- 단점
- 플래시 블록이 반복적인 쓰기 작업 후 노화해서 SSD도 노후할 가능성이 있다.
- 30배 더 비싸다
- 저장 용량이 상당히 적다
6.2 지역성
- 시간 지역성
- 공간 지역성
- 좋은 지역성을 갖는 프로그램이 나쁜 지역성을 갖는 프로그램 보다 더 빨리 돌아간다.
- 하드웨어 수준 - 최근 참조한 인스트럭션과 데이터 아이템의 블록을 저장하고 있는 캐시 메모리 도입
- 운영체제 수준 - 메인 메모리를 가장 최근에 참조한 가상 주소 공간 블록에 대한 캐시로 사용
Stride-1 패턴
- 벡터의 각 원소를 순차적으로 방문하는 참조 패턴 - 순차 참조 패턴
- 연속적인 벡터의 매 k번째 원소를 방문하는 것을 Stride-k 참조 패턴이라고 부른다.
- 이중으로 중첩된 루프는 배열의 원소들을 행 우선으로 읽는다.
메모리 계층구조
- 각 k에 대해 레벨 k에 있는 보다 빠르고 더 작은 저장장치가 레벨 k+1에 있는 더 크고, 더 느린 저장장치를 위한 캐시서비스를 제공한다.
- 레벨 k+1에서 저장장치는 블록이라고 하는 연속된 데이터 객체 블록으로 나뉜다. 각 블록은 유일한 주소 또는 이름을 가진다.
- 레벨 k에서의 저장장치는 레벨 k+1에 있는 블록들과 같은 크기인 더 작은 집합의 블록으로 나뉜다.
- 데이터는 항상 레벨 k와 k+1 사이에서 블록 크기의 전송 유닛 단위로 복사된다. 블록 크기가 계층구조의 인접한 모든 쌍들 사이에서 고정되어 있는 반면, 다른 레벨의 쌍은 서로 다른 블록 크기를 가질 수 있다.
캐시적중/미스
- 어떤 프로그램이 레벨 k+1로부터 특정 데이터 객체 d를 필요로 할 때 먼저 현재 레벨k에 저장된 블록들중 하나에서 d를 찾는다 있으면 캐시적중 없으면 캐시미스라고 한다.
- 캐시가 어떤 요청이 적중인지 미스인지 결정하고 요청한 워드를 뽑아내기 위해 수행하는 과정
- 집합선택
- 라인매칭
- 워드추출
캐시 메모리 구조
- S : 캐시 집합 배열
- E : 집합을 이루는 라인
- B : 각 라인의 데이터 블록
- m : 고유의 주소를 구성하는 m비트
직접 매핑 캐시
- 집합 당 정확히 한 개의 라인을 가지는 경우
집합 결합성 캐시
- 각 집합이 하나 이상의 캐시라인을 갖는다.
- 1<E<C/B 인 캐시는 E중 집합 결합성 캐시라고 부른다.
완전 결합성 캐시
- 모든 캐시라인들을 갖는 하나의 집합
쓰기 이슈
- write-through : 매 쓰기마다 버스트래픽 발생
- write-back : 버스트래픽을 줄이지만 좀 더 복잡하다.
백준
2605
#include <bits/stdc++.h>
using namespace std;
int main()
{
ios_base::sync_with_stdio(false); cin.tie(NULL); cout.tie(NULL);
int n, x;
vector<int> v;
cin >> n,'\\n';
for(int i = 1; i<=n; ++i)
{
cin >> x;
v.insert(v.begin() + x, i);
}
for(int i = n-1; i>=0 ; --i)
{
cout << v[i] << ' ';
}
return 0;
}
- Vector 사용법을 몰라 접근하지 못했던 문제. 벡터의 사용법을 배워보도록 하자
C++
Vector Container
- 자동으로 메모리가 할당되는 배열
Vector의 초기화
vector<자료형> 변수명 벡터 생성
| vector<자료형> 변수명(숫자) | 숫자만큼 벡터 생성 후 0으로 초기화 |
| vector<자료형> 변수명 = { 변수1, 변수2, ..} | 벡터 생성 후 오른쪽 변수 값으로 초기화 |
| vector<자료형> 변수명[] = {,} | 벡터 배열(2차원 벡터) 선언 및 초기화(열 고정, 행가변 |
| vector<vector<자료형>> 변수명 | 2차원 벡터 생성(열과 행 모두 가변) |
| vector<자료형>변수명.assign(범위, 초기화할 값) | 벡터의 범위 내에서 해당 값으로 초기화 |
Vector의 Iterators
v.begin() 벡터 시작점의 주소 값 반환
| v.end() | 벡터 (끝부분 + 1) 주소값 반환 |
Vector Element Access(벡터의 요소 접근)
v.at(i) 벡터의 i번째 요소 접근(범위 검사o)
| v.[i] | 벡터의 i번째 요소 접근(범위 검사x) |
| v.front() | 벡터의 첫 번째 요소 접근 |
| v.back() | 벡터의 마지막 요소 접근 |
- at과 []의 차이점
- 둘 다 같은 n번째 요소 접근이지만 at는 범위를 검사하여 범위 밖의 요소에 접근 시 예외처리를 발생시킨다. []는 범위검사를 하지 않으며 예외처리를 발생시키지 않는다. 또한 해당범위 밖의 요소에 접근을 시도한다면 일반적인 디버깅(g++ or VC++)이 발생한다.
Vector에 요소 삽입/제거
v.push_back() 벡터의 마지막 부분에 새로운 요소 추가
| v.pop_back() | 벡터의 마지막 부분 제거 |
| v.insert(삽입할 위치의 주소 값, 변수 값) | 사용자가 원하는 위치에 요소 삽입 |
| v.emplace(삽입할 위치의 주소 값, 변수 값) | 사용자가 원하는 위치에 요소 삽입(move 로 인해 복사생성자 x) |
| v.emplace_back() | 벡터의 마지막 부분에 새로운 요소 추가(move로 인해 복사생성자x) |
| v.erase(삭제할 위치) or v.erase(시작 위치, 끝 위치) | 사용자가 원하는 index값의 요소를 지운다. |
| v.clear() | 벡터의 모든 요소를 지운다.(return size =0) |
| v.resize(수정 값) | 벡터의 사이즈를 조정한다.(범위 초과시 0으로 초기화) |
| v.swap(벡터 변수) | 벡터와 벡터를 스왑한다. |
Vector Capacity(벡터 용량)
v.empty() 벡터가 빈공간이면 true, 값이 있다면 false
| v.size() | 벡터의 크기 반환 |
| v.capacity() | heap에 할당된 벡터의 실제크기(최대크기) 반환 |
| v.max_size() | 벡터가 system에서 만들어 질 수 있는 최대 크기 반환 |
| v.reserve(숫자) | 벡터의 크기 설정 |
| v.shrink_to_fit() | capacity의 크기를 벡터의 실제 크기에 맞춘다. |
삼항 연산자(ternary operator)
- 삼항 연산자는 다른 언어에는 존재하지 않는 C언어와 C++만의 독특한 연산자이다.
지속성 접근시간 민감한지 비트당 트랜지스터 수 비용
| SRAM | YES | 1X | NO | 6 | 1000X |
| DRAM | NO(refresh) | 10X | YES | 1 | 1X |
- C++에서 유일하게 피연산자를 세 개나 가지는 조건 연산자이다.
- 간단하게 if-else문을 대체할 수 있다.
문법
조건식 ? 반환값1 : 반환값2
- 물음표(?) 앞의 조건식에 따라 결괏값이 참(true)이면 반환값 1을 반환하고, 결괏값이 거짓(false)이면 반환값2를 반환합니다.
Keyword
메모리 할당 정책
- 메모리 할당 정책은 메모리 할당 및 해제를 처리하는 방법이나 알고리즘을 말한다. 메모리 할당 정책은 시스템의 성능과 메모리 사용의 효율성에 영향을 미친다.
- 종류
- first-fit : 가장 처음으로 충분한 크기의 빈 공간을 찾아 할당한다.
- next-fit : 이전 할당된 메모리의 위치부터 순차적으로 빈 공간을 검색해서 할당한다.
- next-fit이 first-fit보다 최악의 메모리 이용도를 갖는다는 것으로 밝혀졌다.
- best-fit : 충분한 크기의 빈 공간 중에서 가장 작은 공간을 선택해 할당한다.
- worst-fit : 충분한 크기의 빈 공간 중에서 가장 큰 공간을 선택해 할당한다.
- buddy allocation : 빈 공간을 2의 거듭 제곱 크기로 나누어 관리하고, 작은 공간을 찾아 큰 공간을 분할하거나 합치는 방식으로 할당한다.
- slab allocation : 고정된 크기의 객체들을 일정한 크기의 캐시로 관리하고, 할당 요청이 있을 대 해당 캐시에서 객체를 할당한다.
묵시적 리스트
- 모든 할당기는 블록 경계를 구분하고, 할당된 블록과 가용 블록을 구분하는 데이터 구조를 필요로 한다.
- 대부분의 할당기가 해당 정보를 블록 내부에 저장한다.
- 일반적인 방법으로는 추가적으로 1블록을 사용하여 블록 앞에 블록의 크기를 저장하는 방법이 있다.
- 이때 추가적으로 사용되는 1워드를 헤더라고 한다.
- 헤더는 블록 크기와 블록이 할당되었는지, 혹은 가용 상태인지를 인코딩한다.
- 헤더 다음에는 데이터가 존재한다.
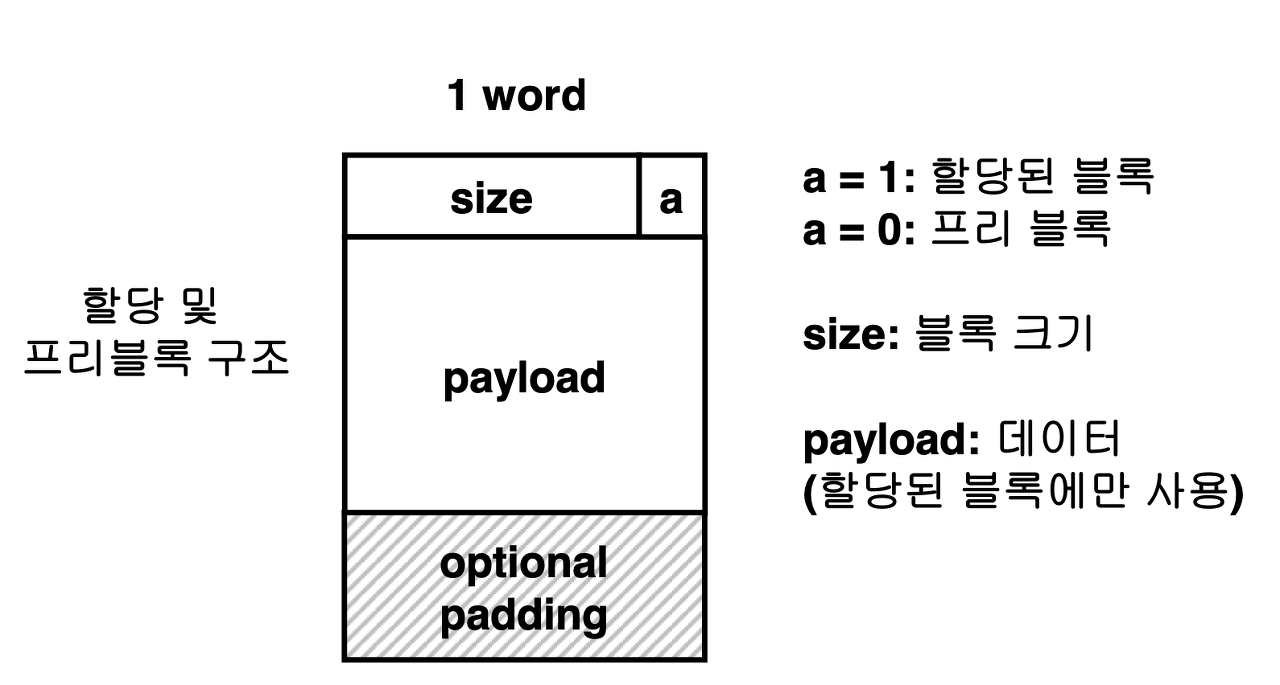
- 데이터 이후에는 사용되지 않은 패딩이 따라올 수 있는데, 이들의 크기는 가변적이다.

- 이러한 구조를 묵시적 리스트라고 부르는데, 그것은 가용 블록이 헤더 내 필드에 의해서 묵시적으로 연결되기 때문이다.
- 특별히 마지막 블록이 필요하다는 점에 유의해야한다.
- 이를 에필로그 헤더라고 부른다.
- 장점
- 단순하다
- 단점
- 가용 리스트를 탐색해야 하는 연산들의 비용이 힙에 있는 전체 할당된 블록과 가용 블록의 수에 비례한다는 것이다.
명시적 리스트
- 가용 블록들을 이전 가용 블록과 다음 가용 블록을 가리키는 포인터를 가진 일종의 이중 연결 링크드 리스트 자료구조로 구성하는 방법이다.
- 가용 블록은 프로그램에서 사용되지 않기 때문에, 해당 자료구조를 구현하는 포인터들은 가용블록의 본체 내에 저장 될 수 있다.
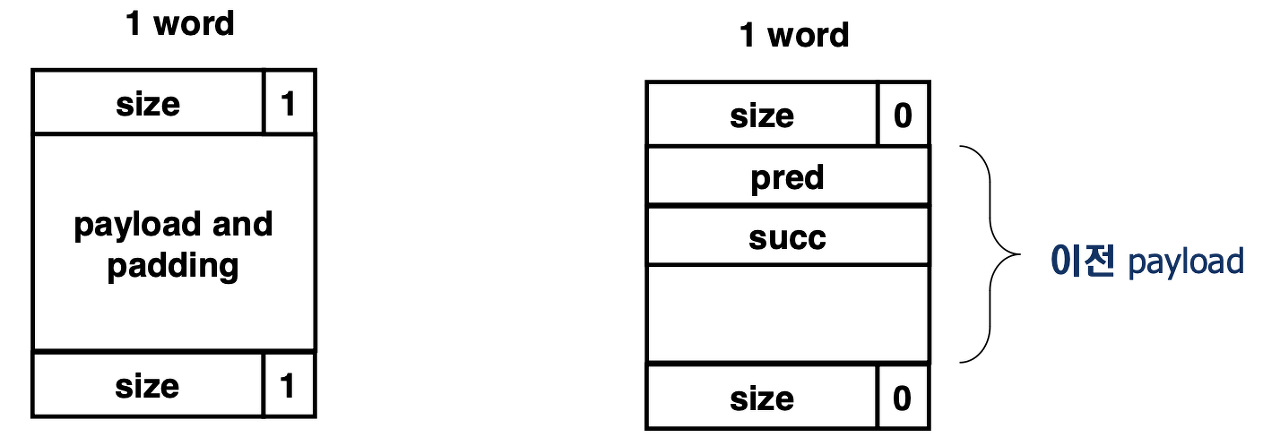
- 할당된 블록의 구조는 묵시적 리스트 방식과 동일하며, 단지 가용 블록의 구조만 바뀌는 것에 유의해야 한다.

- first fit 할당 시간을 전체 블록 수에 비례하는 것에서 가용 블록의 수에 비례하는 것으로 줄일 수 있다.
demand-zero memory
- 필요할 때(demand) 할당하고 0으로 초기화해주는(zero) 메모리를 말한다.
- 어떤 자원을 요청하거나 동장을 요청했을 때, 그것이 정말 필요해질 때 까지 실제 자원을 할당하거나 동작을 실행하지 않는 것을 의미한다.
- 즉, 우리가 kernel에게 메모리를 할당해달라고 요청하면(sbrk) kernel은 거의 아무것도 하지 않고(특정한 VM영역이 할당되었다는 최소한의 표시만 해두고) 우리에게 할당이 끝났다고 알려준다. 실제 메모리는 할당되지 않은 상태로 남아있게 된다.
- 이렇게 되면 유저는 메모리가 할당된줄알고 해당 주소에 뭔가를 쓰거나 읽을텐데, 처음 읽거나 쓰려고 하는 순간 실제 메모리(페이지)가 할당되어있지 않기 때문에 page fault가 발생할 것이고, 그제서야 kernel은 사용하지 않는 메모리(페이지)를 할당하고 0으로 채운뒤에 유저가 원래 하려고 했던 명령어를 다시 실행하게 된다.
728x90
'Study > TIL(Today I Learned)' 카테고리의 다른 글
| 24.02.16 간단한 정리, 코드리뷰에 대해, 백준, C++ (0) | 2024.02.17 |
|---|---|
| 24.02.15 간단한 정리, 백준 (0) | 2024.02.15 |
| 24.02.13 CSAPP 9 (3) | 2024.02.14 |
| 24.02.12 CSAPP 8, Stack & Queue 구현 (3) | 2024.02.13 |
| 24.02.11 CSAPP 6.1.2 - 6, LinkedList 구현 (9) | 2024.02.12 |